Flutter, Dart, TMDb API, WebView, URL Launcher, SharedPreferences, Git, GitHub
DramaBuddy was inspired by my love for Korean Dramas and the need for a single, mobile first app to track, rate, and discover content. The goal is to make drama tracking fun, simple, and visually engaging.
Overview
DramaBuddy is a K-Drama tracking and discovery application built with a strong focus on clarity, usability, and mobile-first design. The app allows users to manage their watchlist, track viewing progress, and explore new content through structured metadata and social-inspired discovery.
The project is designed as a scalable product with future App Store release in mind.
What it does
DramaBuddy provides tools to help users manage their drama experience:
- Organize shows by Watching, Completed, and Planned
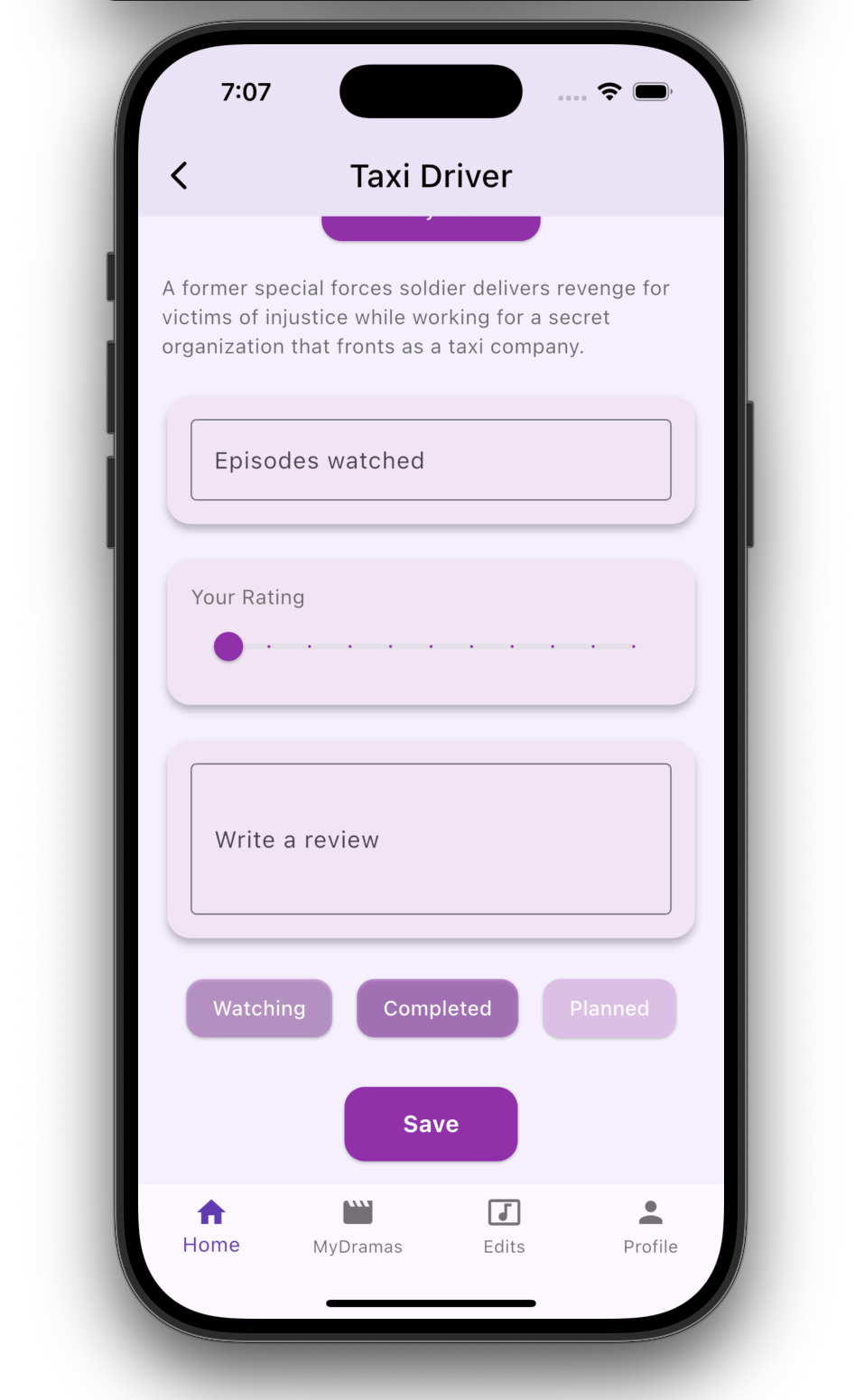
- Track episode progress per show
- Add private ratings and notes
- Discover dramas using curated metadata
- Explore trending drama-related content
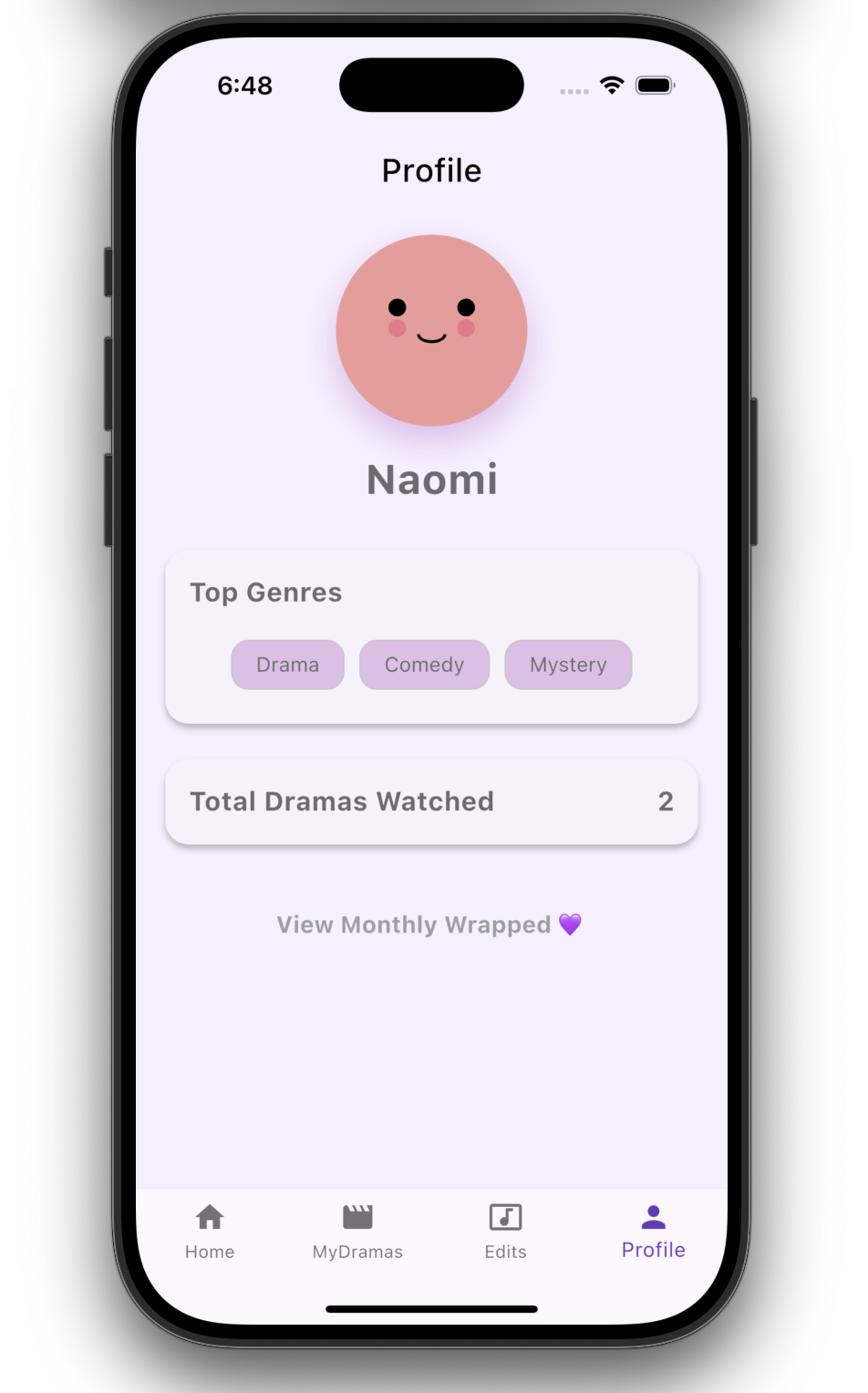
- View a visual Monthly Wrapped summary
Screens
Core Experience
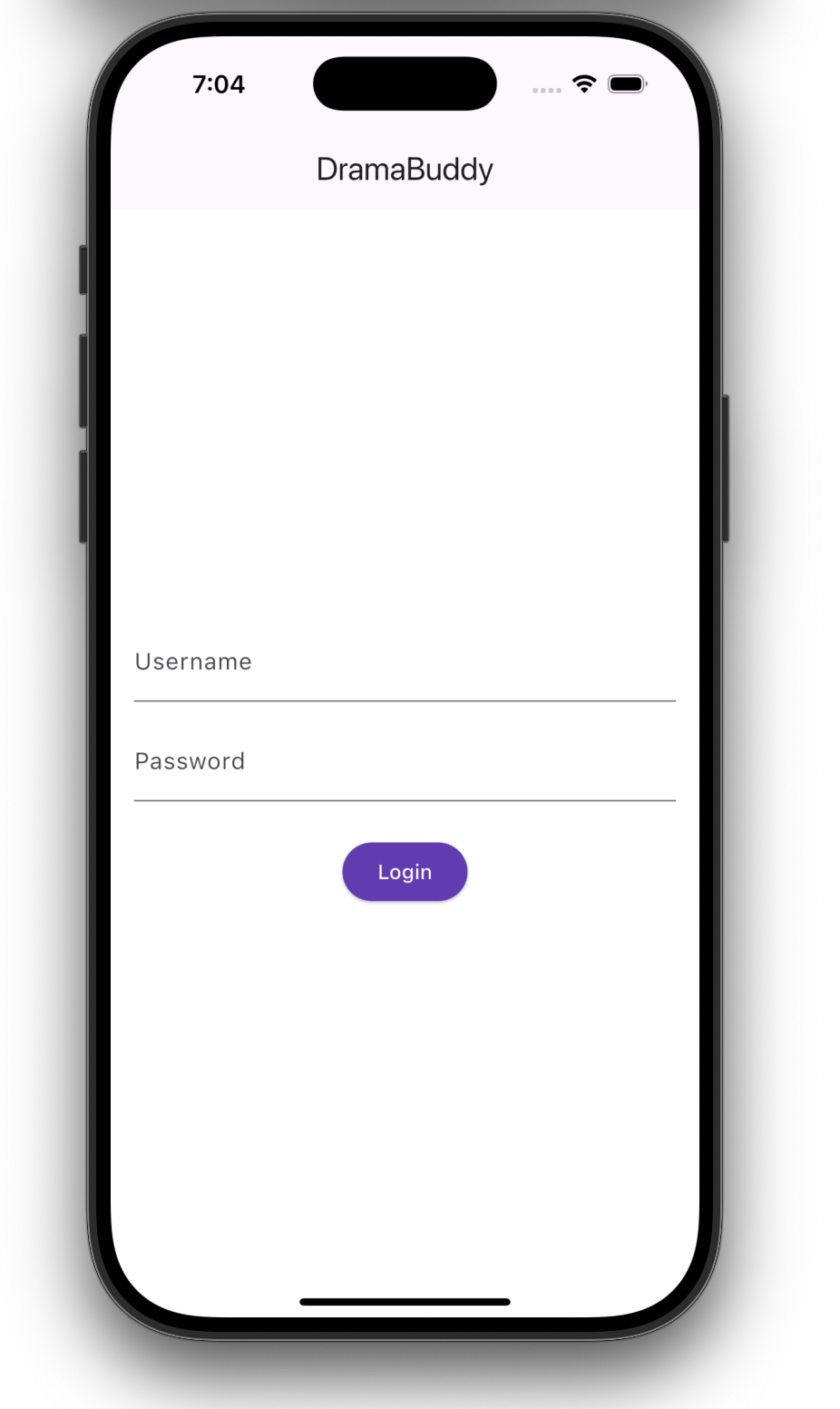
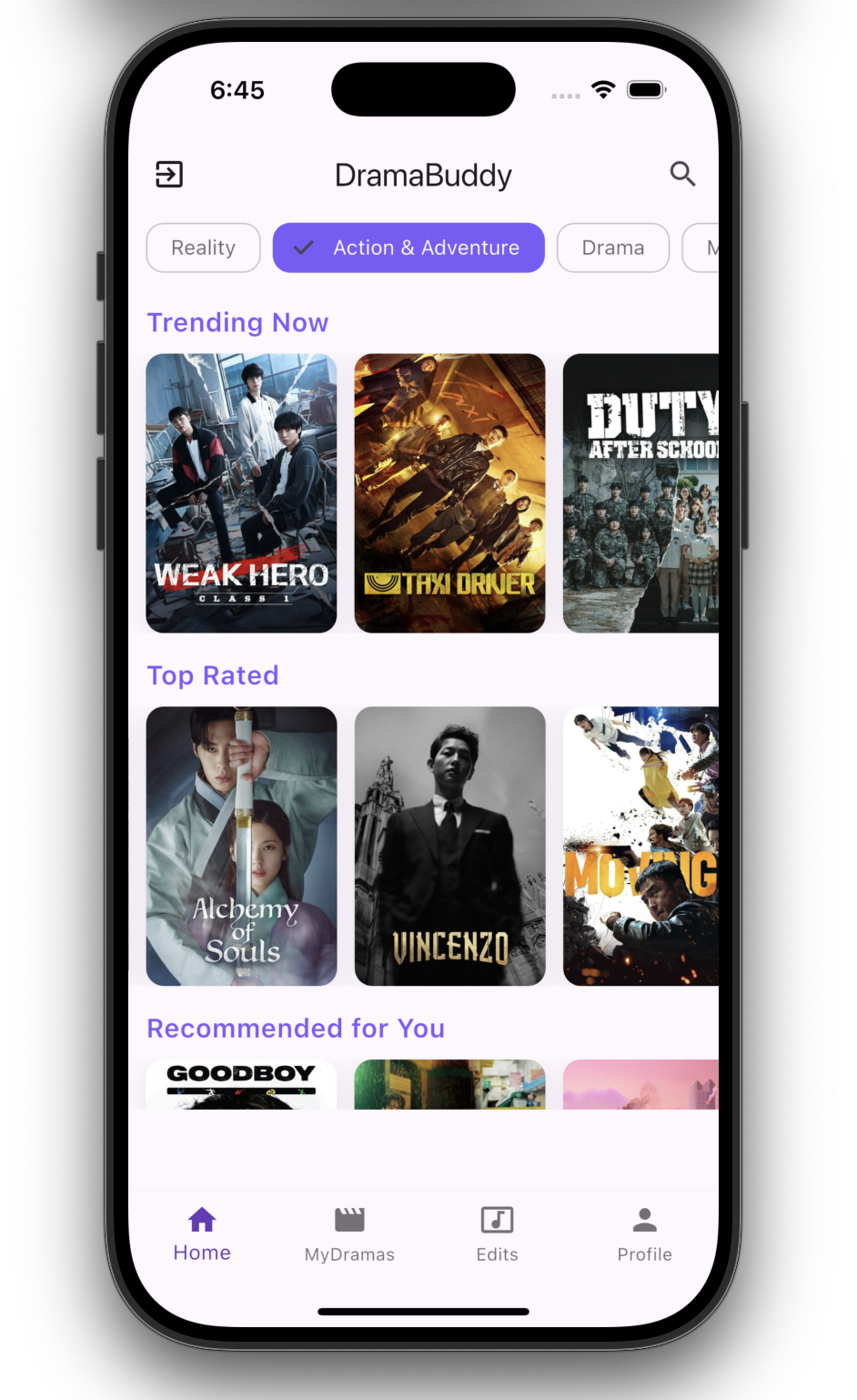
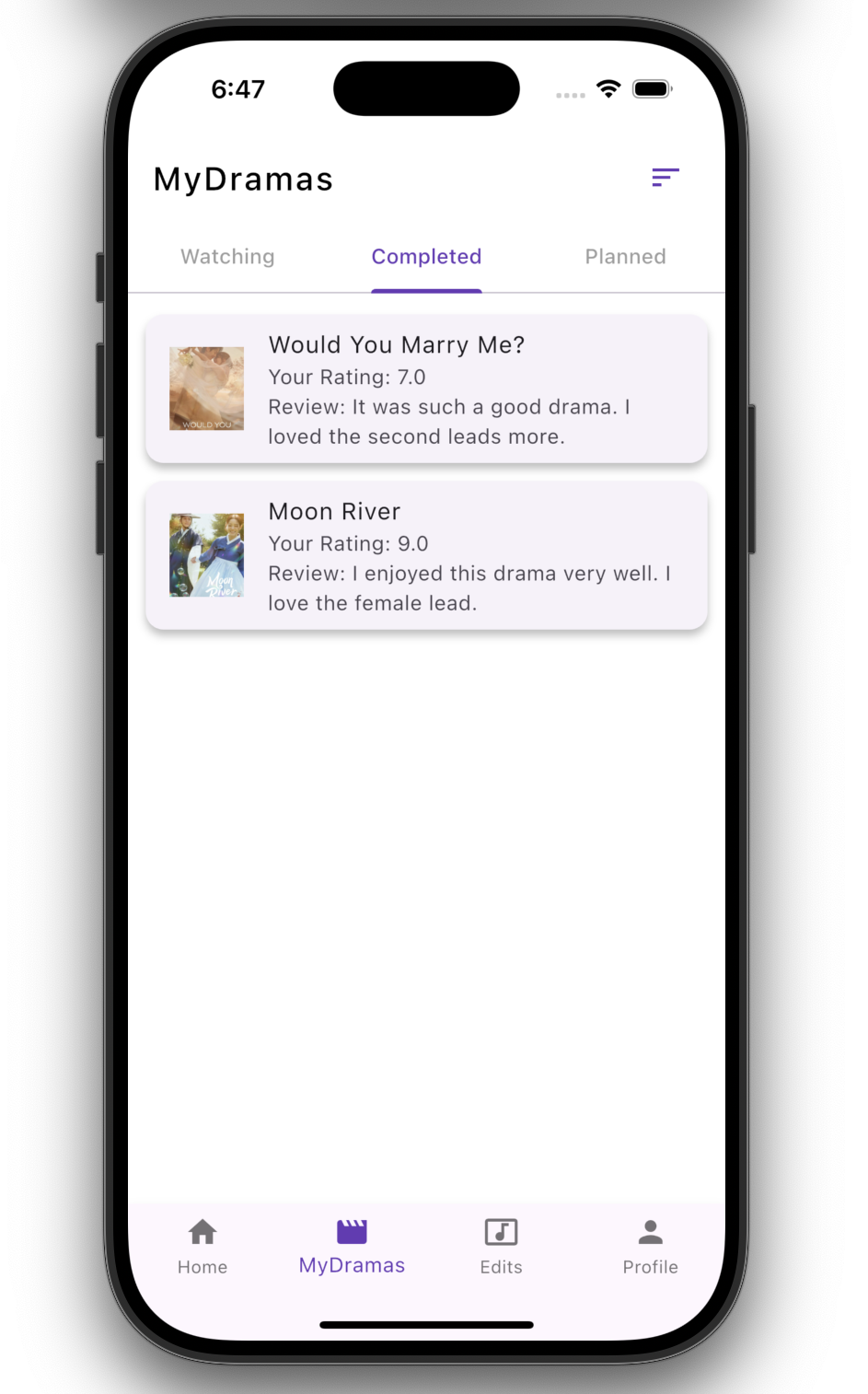
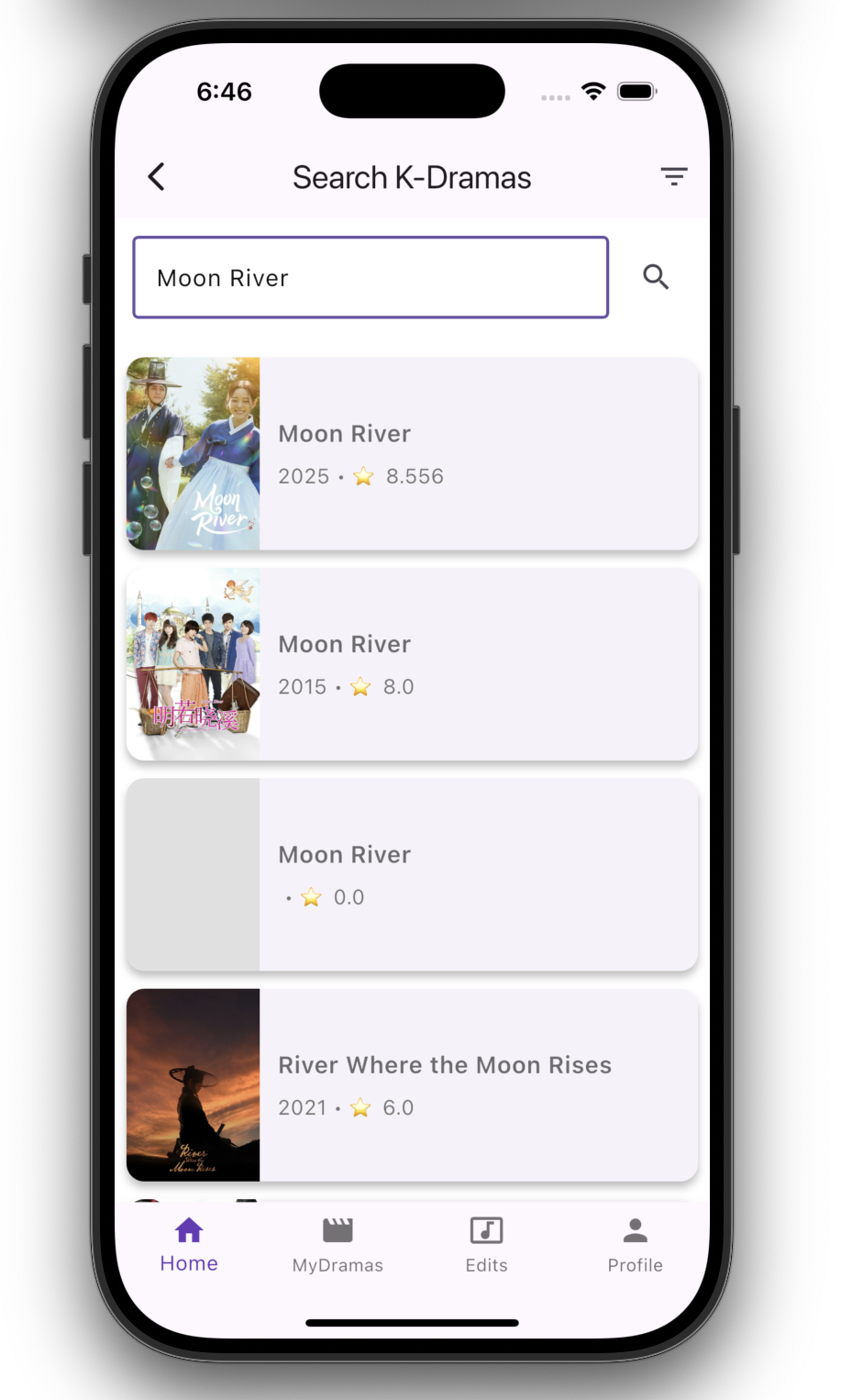
Discovery & Profile
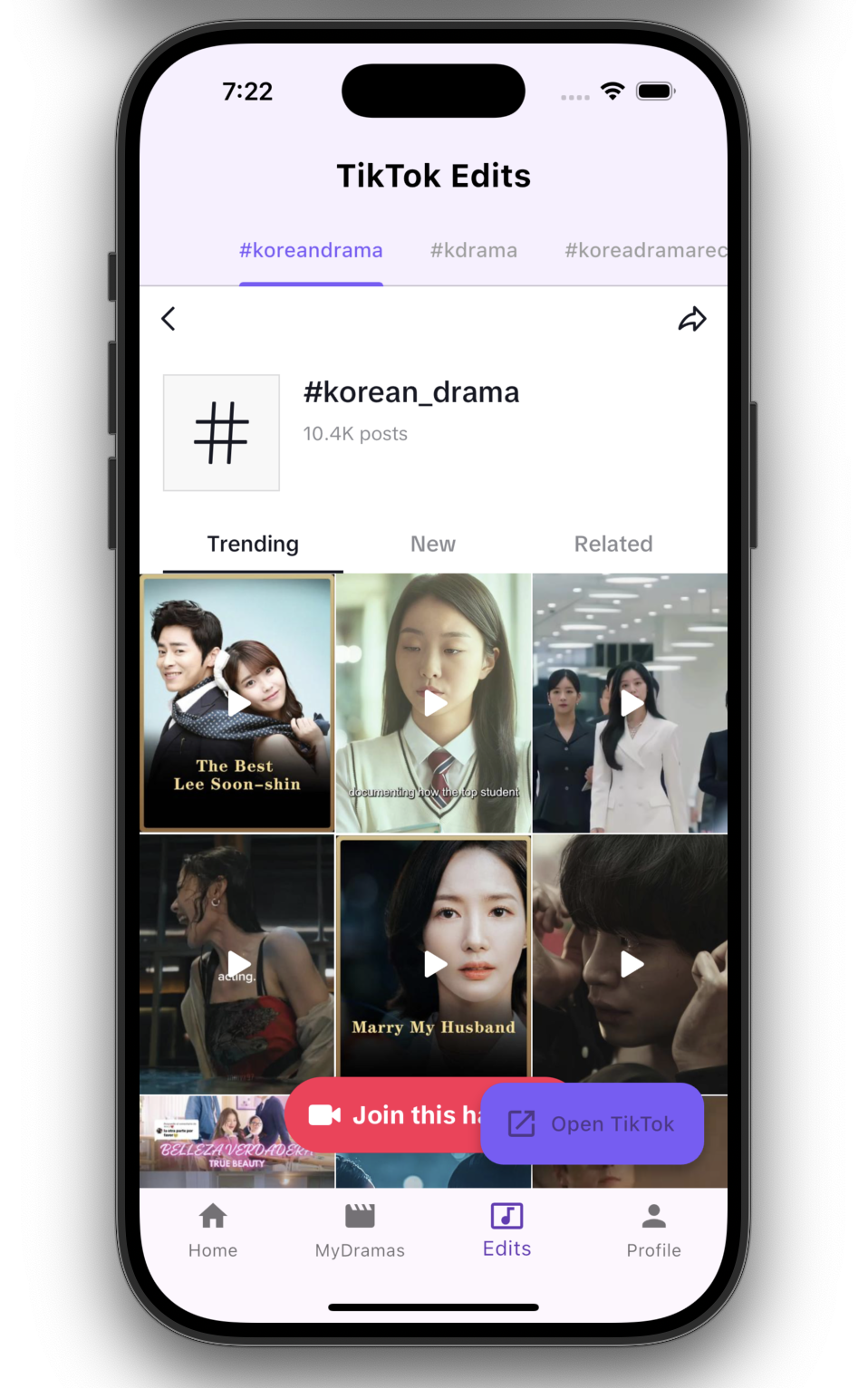
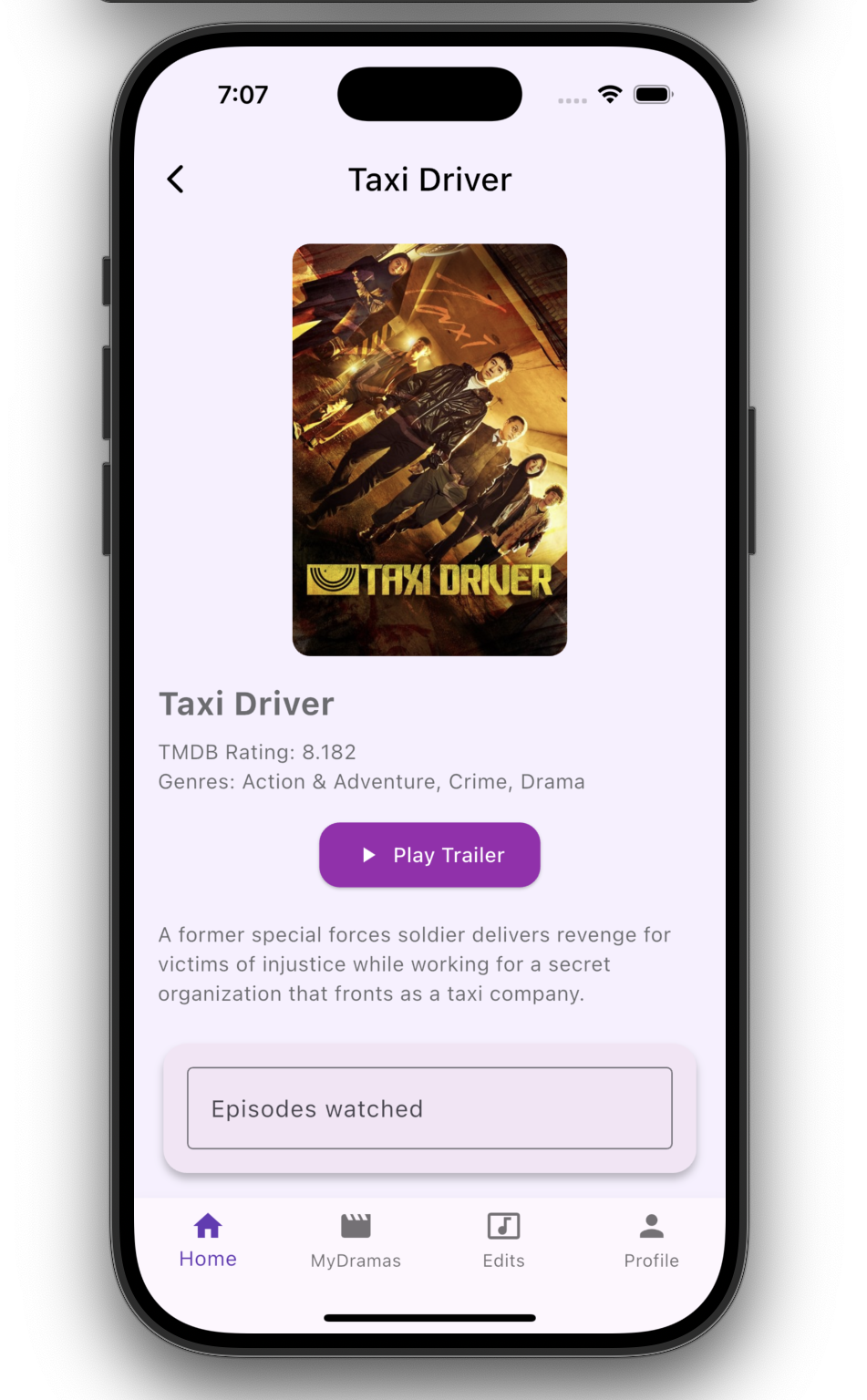
Details & Insights
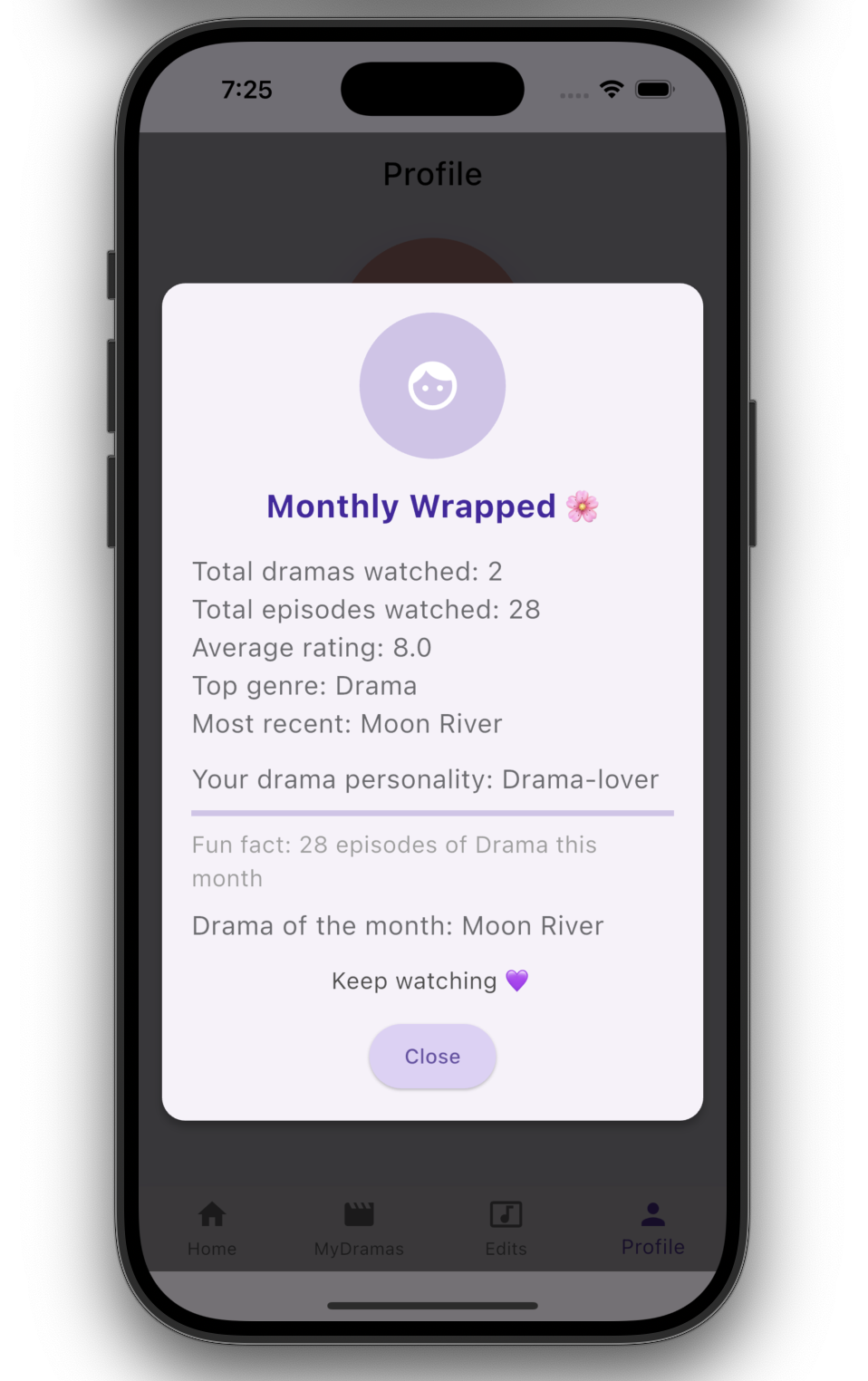
Product & Design Focus
DramaBuddy emphasizes:
- A minimal, iOS-inspired interface
- Clear information hierarchy
- Smooth navigation between sections
- Visual consistency across screens
- Thoughtful empty and loading states
The design prioritizes approachability and ease of use over complexity.
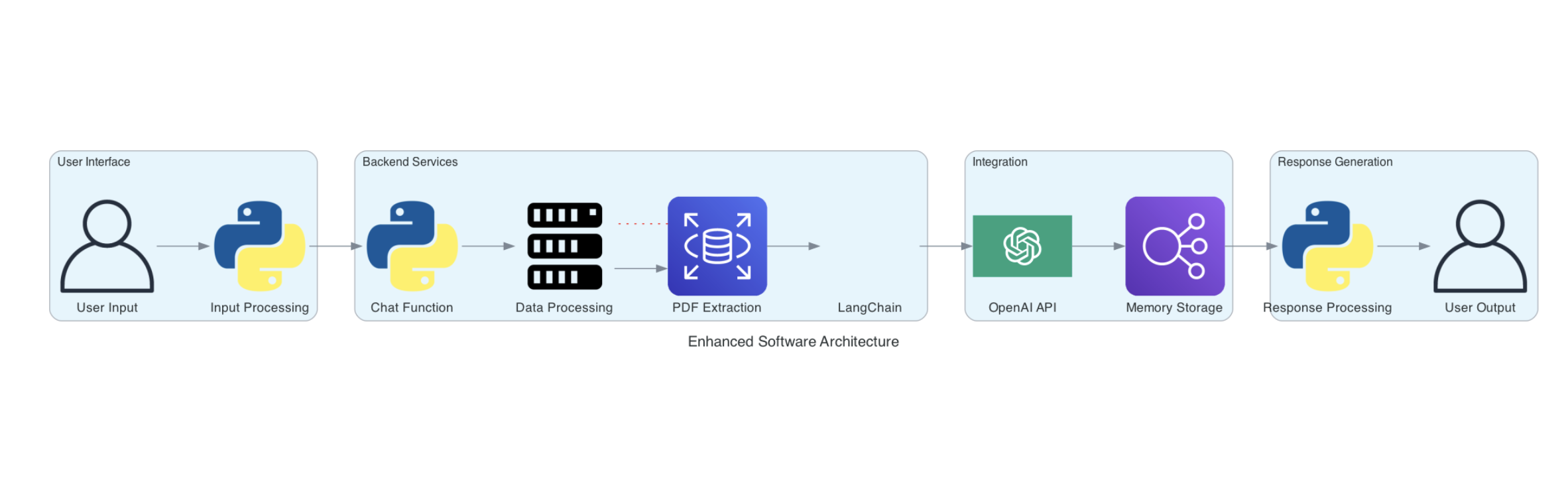
Technical Approach
The application is built using modern mobile development practices:
- Cross-platform development with Flutter
- Modular UI components for reusability
- External API integration for metadata
- Local persistence for user data
- Separation between presentation and data layers
Implementation details are intentionally abstracted at this stage.
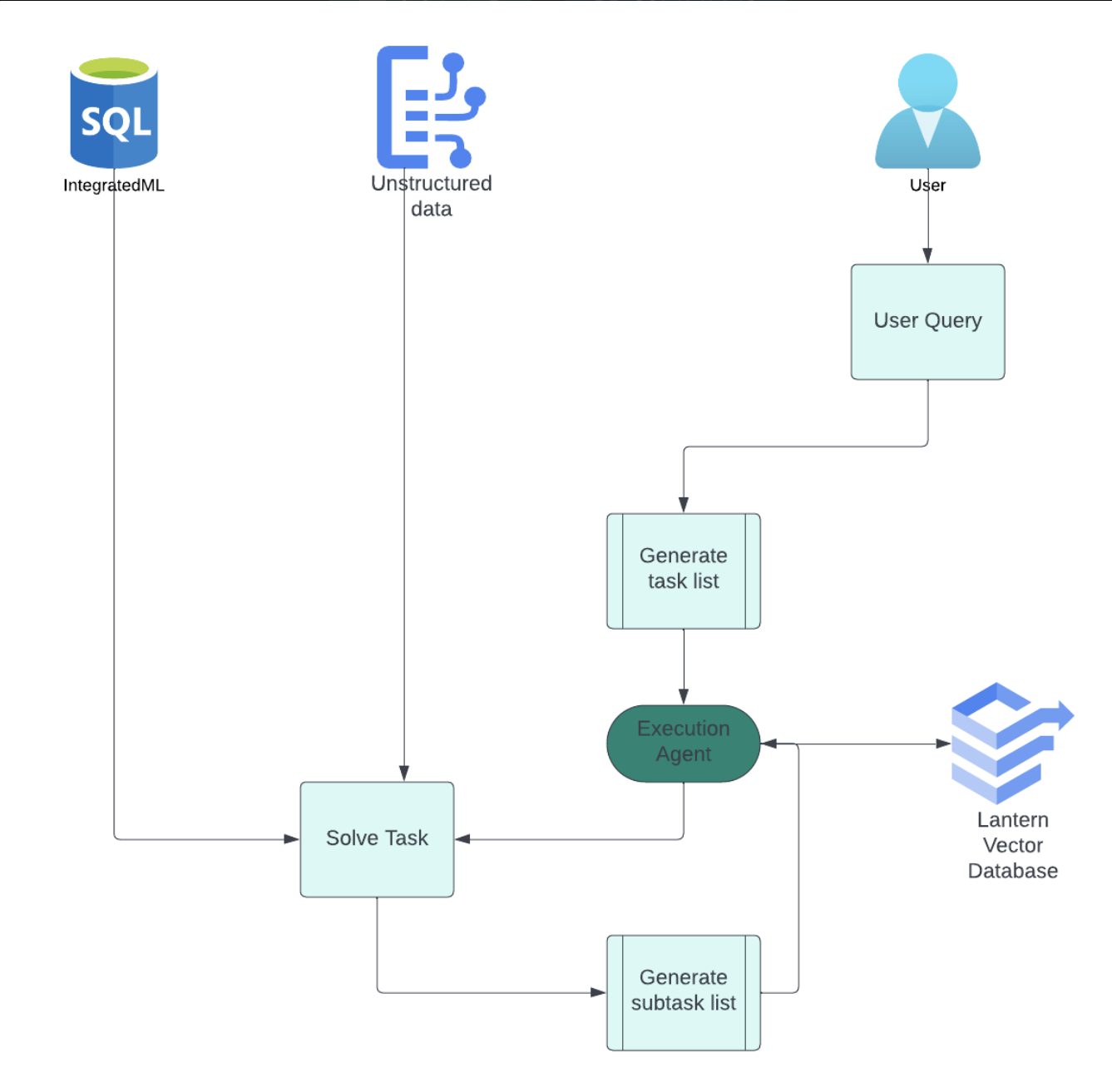
Architecture Overview
DramaBuddy follows a layered architecture:
- Presentation Layer: Screens and reusable UI components
- Domain Layer: Models representing dramas and user state
- Data Layer: Services responsible for fetching and storing data
This structure supports maintainability and future feature expansion.
What I focused on
- Designing a product-ready mobile experience
- Balancing feature richness with simplicity
- Creating a foundation suitable for App Store deployment
- Thinking beyond a demo toward a real consumer app
Future Direction
Planned enhancements include:
- User authentication and cloud sync
- Smart recommendations
- Push notifications for new content
- Shareable viewing summaries
- App Store release
Acknowledgments
- Korean Drama Industry: For the creative work that inspired the product concept
- Flutter Ecosystem: For tools and open-source packages
- Mobile Design Community: For iOS UI and UX inspiration